Cambiar de contexto entre ramas siempre ha sido costoso. git stash, hacer checkout de la rama y volver a levantar el entorno local se come entre cinco y quince minutos. Pierdes el hilo, los archivos que tenías abiertos quedan desactualizados, y el estado de la base de datos que estabas depurando se fue. El arreglo de siempre es ser disciplinado con el stash y mantener el árbol de trabajo limpio. Eso funciona bien cuando eres el único que sostiene el contexto.
Con un agente de IA en el ciclo, el costo crece de una forma que no recibe suficiente atención. Los agentes de IA para código (Claude Code, Codex, Gemini CLI, OpenCode) construyen un entendimiento de tu base de código dentro de la sesión. A lo largo de minutos u horas acumulan contexto: cuáles archivos importan para la tarea, el plan que vienen ejecutando a medias, las invariantes que han deducido de un subsistema, las pruebas en las que han aprendido a confiar. Nada de eso está escrito en ningún lado. Vive en la sesión, anclado a los archivos en disco.
Cuando el directorio de trabajo cambia, un cambio de rama que reemplaza cada archivo versionado, el contexto del agente pierde su ancla. Un archivo que venía leyendo sigue existiendo en la misma ruta, así que nada falla, pero el código adentro puede haber sido reescrito. El plan que el agente estaba ejecutando asumía una versión de la base de código que ya no está en disco. Lo más seguro que puede hacer el agente es releer los archivos críticos antes de continuar. Eso cuesta tiempo, tokens y atención. Nos volvimos buenos haciendo a los agentes productivos y olvidamos que la gestión de ramas le pone un techo a esa productividad.
El arreglo es más viejo que los agentes. Un git worktree le da a cada rama su propio directorio, y un script de setup ligero convierte ese directorio en un entorno de trabajo en lugar de un checkout pelado. Este post trata de las dos mitades, y de por qué los comandos de worktree que traen Claude Code y Codex solo resuelven la primera.
Qué es un Worktree
git worktree te permite tener varias ramas del mismo repositorio en checkout, cada una en su propio directorio, sin clonar el repo por segunda vez. El historial .git por debajo es compartido: commits, ramas y remotes son un solo almacén. Los archivos de trabajo no.
# Cambio de rama tradicional
git stash
git checkout hotfix-branch
# ... trabajo ...
git checkout feature-branch
git stash pop
# Equivalente con worktree
cd project/.worktrees/hotfix-branch/
# ... trabajo ...
cd project/
# la feature branch sigue ahí, intactaSin stash. Sin cambiar. Ambas ramas existen en disco al mismo tiempo, y se puede trabajar en las dos en paralelo. Lo que más importa para el trabajo con IA: cada rama tiene su propio directorio, así que cada rama puede hospedar su propia sesión de agente, y esa sesión se mantiene estable sin importar lo que pase en el otro directorio.
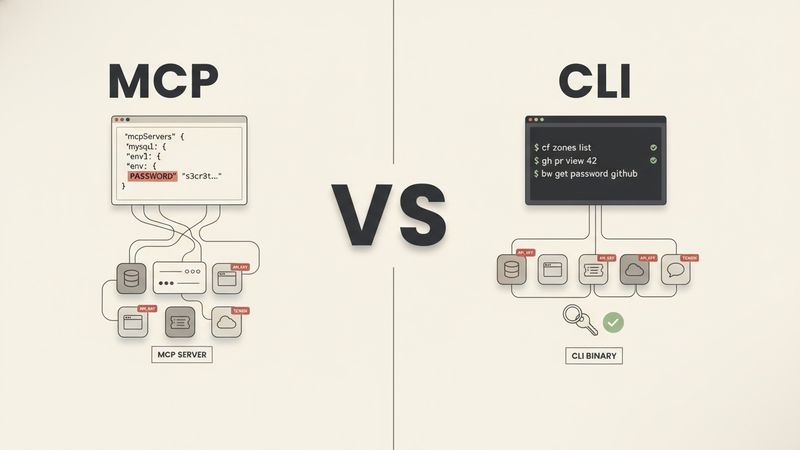
La Pieza que los Worktrees Nativos No Resuelven
Claude Code tiene EnterWorktree. Codex puede crear worktrees. Ambos sirven. Hacen el paso crudo de git worktree add. Pero git worktree add a secas te da un directorio con una rama en checkout. No te da un entorno de desarrollo funcional.
Piensa en lo que necesita una rama recién sacada:
- Setup de Docker: puertos únicos para que dos worktrees no choquen, un nombre de proyecto de Compose aparte, dependencias instaladas.
- Archivos de entorno: valores de
.envacotados al worktree (URLs de base de datos, API keys que apuntan al puerto local correcto). - Instalación de dependencias: lo que difiere entre la rama base y la rama feature puede requerir
npm ci,composer installouv sync. - Contexto del agente de IA: el CLAUDE.md, las skills, los hooks y las configuraciones de agente que viven en el directorio principal del proyecto. Sin ellos, el agente dentro de un worktree se comporta como un recién contratado en su primer día.
Las herramientas nativas de worktree se saltan todo esto. Resuelven el problema de git pero no el problema del entorno de desarrollo, y para trabajo práctico asistido por IA el problema del entorno es la parte difícil.
No es teoría. La skill de worktree en mi workspace principal trae una nota que explica que su paso de enlazado de configuración existe precisamente para reparar worktrees creados por EnterWorktree de Claude Code, que aparecen sin los symlinks de configuración de IA. El builtin crea el directorio. Igual te toca hacerlo habitable. Esa brecha es la razón completa por la que existe un wrapper.
No todos los proyectos sufren con esto. Los proyectos en Go compilan rápido y casi no tienen entorno de desarrollo local del que hablar. Un solo go run y ya estás en la rama nueva. Scripts de infraestructura, modelos de dbt, cambios rápidos de SQL: nada de esto necesita herramientas de worktree. El beneficio aparece cuando tu proyecto tiene un setup local no trivial que toma minutos reconstruir entre ramas.
Cómo Lo Resuelvo
Todo lo que sigue es el wrapper wt que escribí para mis propios proyectos. Léelo como un ejemplo trabajado, no como una herramienta para instalar. Tu stack va a querer una mezcla distinta de estas piezas, y el valor está en ver qué piezas existen y cuándo cada una se gana su lugar.
El wrapper hace lo que el tipo de proyecto necesite y nada que no necesite. Un stack pesado en Docker necesita puertos y nombres de Compose. Un proyecto en Go casi no necesita nada. El truco es una sola herramienta que escala desde “hacer todo” hasta “no hacer nada” según el proyecto, así solo mantienes un flujo de trabajo.
Asignación de Puertos
Los conflictos de puertos de Docker son lo primero que se rompe cuando dos copias de un proyecto corren en la misma máquina. El wrapper asigna puertos de forma determinista:
my-api/ # main: puerto 8000
my-api/.worktrees/FEAT-101/ # worktree: puerto 8001
my-api/.worktrees/BUG-204/ # worktree: puerto 8002El directorio de trabajo principal conserva el puerto por defecto del proyecto. Cada worktree nuevo toma el siguiente puerto libre. Si un puerto ya está ocupado por cualquier cosa en la máquina, el wrapper lo salta y toma el siguiente. Cuando se elimina un worktree, su puerto vuelve a la bolsa.
Cada worktree también recibe su propio nombre de proyecto de Docker Compose, derivado del nombre de la rama:
COMPOSE_PROJECT_NAME=worktree-bug-204Así, docker compose up -d en dos worktrees produce dos copias independientes del servicio que nunca chocan en contenedores ni puertos. (Si ambos apuntan a la misma base de datos de desarrollo compartida, esa es una decisión aparte, no un efecto secundario de los worktrees. Más sobre esto abajo.)
Setup Específico por Tipo de Proyecto
Los lenguajes difieren, así que un setup único para todos no funciona. El wrapper detecta el tipo de proyecto y corre el bootstrap correcto:
- PHP (Docker Compose): fija un
APP_PORTúnico en.env, unAPP_SSL_PORTque cuadre, unCOMPOSE_PROJECT_NAMEsaneado, y quita los bindings de puerto fijos dedocker-compose.ymlpara que Compose use los valores del.env. Las dependencias de Composer se instalan dentro de Docker. - Python (Django): crea un entorno virtual nuevo, instala requirements, corre migraciones.
- Python (con uv): corre
uv sync. - JavaScript/TypeScript: corre
pnpm install(onpm ci). - Go: no necesita setup. Go maneja las dependencias por módulo.
El wrapper es solo un script en shell o en Go que vive con el proyecto. Cada proyecto define su propia función de setup, y el wrapper despacha según una pista de tipo de proyecto.
Symlinks de Configuración de IA
Los archivos de contexto del agente son la pieza que la mayoría de tutoriales de worktree se saltan, y son la pieza que le permite a la sesión del worktree valerse por sí misma. Un worktree creado con git worktree add no tiene el .claude/skills/, ni el AGENTS.md, ni el .mcp.json, ni los hooks que hacen efectivo al agente.
Esto importa más de lo que parece. Cuando Claude Code o Codex te crean un worktree, el agente que trabaja en él sigue siendo la sesión padre. Las skills, los agentes, los hooks y la configuración de MCP viven en el directorio desde el que arrancaste, no en el worktree. Así que el worktree solo sirve mientras esa sesión padre siga viva. No puedes cerrarla y retomar el trabajo más tarde como una sesión autocontenida dentro del worktree.
Enlazar el framework de IA dentro del worktree elimina esa dependencia. El wrapper enlaza directorios de skills, configuraciones de agente, registros de comandos, archivos de instrucciones (CLAUDE.md, AGENTS.md) y configuraciones de servidores MCP en cada worktree al momento de crearlo. Un archivo se copia en lugar de enlazarse: el archivo de settings local que lleva los valores específicos del puerto. Ahora el worktree carga su propio setup de IA completo. Junto con su propio entorno de desarrollo, puedes abrir una sesión de agente nueva directamente en el worktree, en su propia terminal, y tiene todo lo que tiene el directorio principal. Corre de forma independiente del padre. Puedes cerrar la sesión que lo creó, o mantener varias andando a la vez, cada una su propia sesión de larga duración.
El agente no sabe, ni necesita saber, que está en un worktree. Los hooks se disparan como siempre, y el pipeline de calidad también.
Reciclaje de Puertos al Eliminar
Cuando se elimina un worktree, el wrapper detiene sus contenedores de Docker y libera el puerto. La siguiente creación de worktree ve el puerto liberado y puede asignarlo. Esto mantiene compacto el rango de puertos a lo largo de un ciclo de desarrollo largo.
Un comando aparte de limpieza recorre todos los worktrees, elimina los cuyas ramas ya fueron mergeadas a main, y detiene sus contenedores:
wt cleanup my-api # un proyecto
wt cleanup # todos los proyectos del workspaceCorriéndolo semanalmente, esto evita que los worktrees se acumulen sin tocar el trabajo activo.
Ajusta el Setup a lo que Tu Stack Necesita
El mismo comando wt create <proyecto> <rama> corre en todos los proyectos, pero lo que hace debería seguir al stack. Cada pieza de setup cuesta, así que agrégala solo donde el stack te obligue y tus worktrees se mantienen baratos. Dos ejemplos marcan el rango.
Un proyecto en Go casi no necesita nada. La caché de módulos es global, no hay servicios locales que levantar, y no hay puerto que asignar. La función de setup está vacía. Igual obtienes lo más importante de los worktrees: una sesión independiente por rama y compilación aislada. Aun con setup cero, el mismo wrapper maneja el proyecto, así que no mantienes una segunda herramienta para el caso fácil.
Una app moderna de JavaScript está un escalón más arriba, y enseña la lección opuesta: no escribas maquinaria que no necesitas. Una app basada en Vite no necesita nada de la lógica de colisión de puertos de Docker, porque el servidor de desarrollo ya elige un puerto libre por su cuenta. Asignar puertos a mano acá es esfuerzo gastado peleando un problema que la herramienta ya resolvió. Lo que sí vale la pena es enlazar node_modules con symlink al checkout principal para que cada worktree no reinstale cientos de megabytes de dependencias.
El extremo pesado es un stack de Docker Compose con varios servicios y puertos fijos en el archivo de compose. Ahí es donde el tratamiento completo se gana su lugar: asignar un puerto libre, fijar un nombre de proyecto de Compose único, parchar los bindings de puerto fijos, instalar dependencias en el contenedor. A mano esto son diez a quince minutos de setup cuidadoso y propenso a errores cada vez que empiezas una tarea en paralelo. Automatizado, son unos segundos.
El mismo principio cubre las bases de datos y cualquier otro servicio compartido. Dale al worktree su propia base de datos cuando el trabajo necesite el aislamiento; si no, deja que comparta la del padre. Los worktrees aíslan archivos y procesos, no estado externo, así que aislar ese estado es un paso extra que das solo cuando el trabajo lo pide. Haz lo mínimo que tu stack requiera.
Cómo Adaptarlo a Tu Caso
El setup específico por proyecto es la decisión de diseño clave. En lugar de un script monolítico que conozca cada tipo de proyecto, el wrapper es extensible: agregar soporte para un stack nuevo es escribir una función pequeña que maneje setup y teardown para ese tipo de proyecto.
Esto es lo que hace que una sola herramienta cubra stacks que no se parecen en nada:
- Un equipo con microservicios puros en Go no escribe nada. La función de setup vacía es toda la historia.
- Un equipo con Docker se concentra en la lógica de puertos y Compose e ignora todo lo demás.
- Un equipo de Django agrega creación de virtualenv y pasos de migración sin tocar la configuración de nadie más.
El patrón es: wt create <proyecto> <rama> hace el trabajo de git, y luego le pide a la función de setup registrada del proyecto que prepare el entorno. El registro del proyecto es un archivo de configuración, una línea por proyecto.
Así que lo que te llevas no es mi script. Es la división: haz el trabajo de git una vez, y luego pasa el control a un paso de setup por proyecto que tú escribes para tu propio stack. Yo armé wt alrededor de los proyectos en los que me toca trabajar. Tú deberías armar el tuyo alrededor de los tuyos, con funciones de setup para los stacks que usas y nada para los que no. Son unos cientos de líneas de shell, no un framework. El worktree es la parte universal; el setup siempre va a ser tuyo.
Dónde Rinden Más los Worktrees
| Escenario | Beneficio |
|---|---|
Stacks pesados en Docker donde el setup local toma minutos (APIs en PHP, portales en Django, apps JS con node_modules grandes) | Alto |
| Proyectos en Go, scripts de infraestructura, cambios rápidos de una sola vez | Bajo (pero las sesiones de agente en paralelo igual ayudan) |
| Tickets entre proyectos que tocan varios servicios a la vez | Máximo |
El escenario de mayor beneficio es un ticket entre proyectos que toca una API en PHP, un frontend en JavaScript y un servicio en Python a la vez. Levantas un worktree en cada uno, cada cual en sus propios puertos y con su propia sesión de agente, y te mueves entre ellos cambiando de directorio. Nada choca. La alternativa es hacer malabares con tres ramas y reconstruir tres entornos a mano, algo lo bastante doloroso como para desanimar el trabajo en paralelo por completo.
Los worktrees te quitan ese costo. Cada ticket vive en su propio directorio, con el entorno de Docker y la sesión de agente que necesite justo al lado. Cierras una terminal, abres otra, y todo está donde lo dejaste. El cambio de rama se vuelve un cambio de directorio, y el agente no pierde su lugar.
Un humano que hace malabares con dos ramas lo paga en concentración. Un agente lo paga en corrección: en silencio, porque actúa sobre una base de código que se le movió por debajo. Los worktrees son la forma de dejar de hacérselo pagar.